Introduction
The modern infrastructure landscape demands absolute resilience, making production stability as critical as feature delivery. This comprehensive guide details the Certified Site Reliability Engineer framework, designed for professionals looking to master uptime, automation, and scalable system design. Whether you are a software developer trying to understand production realities, a DevOps practitioner expanding into infrastructure engineering, or a technical leader building a reliable platform team, this analysis will help you navigate your training options. By exploring the certification ecosystem hosted on the sreschool platform, including foundational training available at sreschool and advanced intelligence paradigms taught via aiopsschool, you can make an informed, strategic decision for your career progression.
What is the Certified Site Reliability Engineer?
The Certified Site Reliability Engineer designation represents a practitioner’s verified ability to apply engineering disciplines directly to operations challenges. It exists to bridge the historic gap between rapid software deployment and systemic infrastructure stability. Rather than focusing on purely theoretical infrastructure concepts, this program emphasizes real-world, production-focused learning, telemetry collection, and incident mitigation workflows. It aligns seamlessly with modern cloud-native architectural patterns, distributed systems, and enterprise engineering practices designed to minimize downtime.
Who Should Pursue Certified Site Reliability Engineer?
This certification specifically benefits system administrators, software engineers, DevOps specialists, platform architects, and security professionals who interact with production environments. Beginners looking to establish a structured operational mindset will find clear pathways, while veteran engineers can validate their architectural expertise. Technical managers and enterprise leaders also benefit by gaining the precise vocabulary and strategic framework needed to build metrics-driven operational teams. The curriculum carries strong global relevance and matches the immediate operational needs of technology hubs worldwide, including India’s expanding enterprise tech sector.
Why Certified Site Reliability Engineer
In an era dominated by microservices and complex cloud deployments, tool-specific knowledge degrades rapidly as software ecosystems evolve. The Certified Site Reliability Engineer curriculum offers long-term professional longevity because it teaches core behavioral principles, structural design patterns, and systemic diagnostic methods rather than fleeting software interfaces. Embracing this training helps professionals stay consistently relevant despite rapid shifts in the underlying cloud provider marketplace. The return on your time and financial investment manifests as increased architectural authority, reduced time-to-resolution during outages, and a clear competitive advantage in the enterprise job market.
Certified Site Reliability Engineer Certification Overview
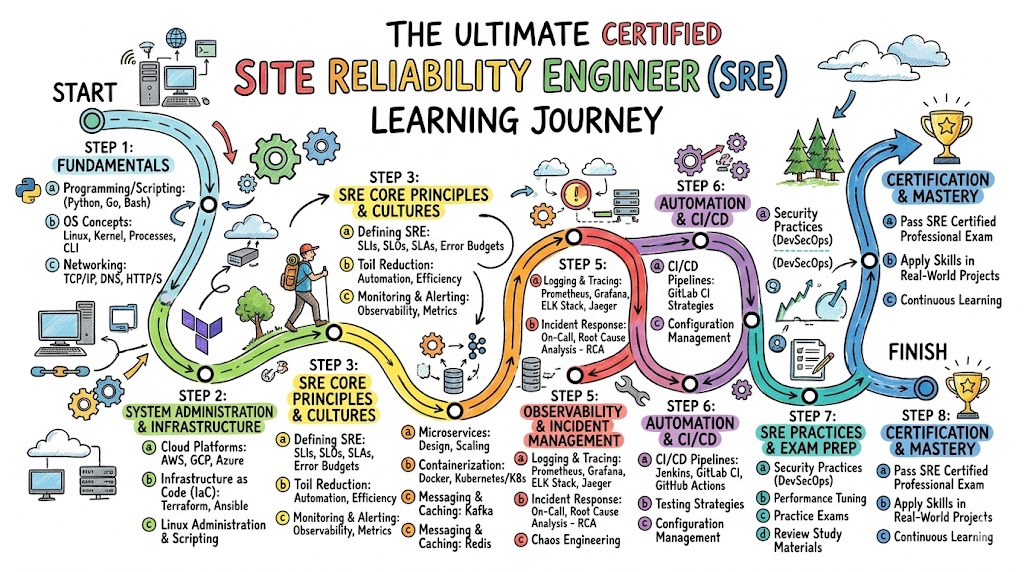
The structured educational program is delivered via the sreschool portal and hosted natively on the sreschool platform. It utilizes a rigorous, performance-based assessment approach that tests practical application over simple rote memorization. Ownership of the certification curriculum ensures that the exams reflect real-world incident responses, configuration scenarios, and systemic architectural design problems. The program structure is broken down into clear, progressive tiers that allow candidates to validate their skills step-by-step as they gain production experience.
Certified Site Reliability Engineer Certification Tracks & Levels
The certification framework is organized into three distinct tiers: foundation, professional, and advanced levels to match your career growth. Specialization tracks allow engineers to focus deeply on core infrastructure management, security integration, intelligence-driven operations, or financial cloud optimization. This multi-tiered structure directly mirrors enterprise engineering hierarchies, allowing an individual to progress from an execution-focused team member to a strategic systems architect.
Complete Certified Site Reliability Engineer Certification Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
| Core SRE | Foundation | Associate Engineers | Basic Linux & Networking | SLOs, SLIs, Post-mortems, Monitoring | First |
| Automation | Professional | DevOps & Systems Engineers | Foundation Certificate | Scripting, CI/CD, Configuration Management | Second |
| Architecture | Advanced | Principal Architects | Professional Certificate | Distributed Systems, Chaos Engineering | Third |
| Observability | Professional | Monitoring Specialists | Foundation Certificate | Tracing, Telemetry, APM, Dashboarding | Concurrent |
| Security | Professional | DevSecOps Engineers | Foundation Certificate | Identity Management, Secret Rotation | Concurrent |
| Financial | Professional | FinOps Practitioners | Foundation Certificate | Cloud Cost Optimization, Budgeting | Concurrent |
Detailed Guide for Each Certified Site Reliability Engineer Certification
Certified Site Reliability Engineer – Foundation
What it is
This credential validates a candidate’s fundamental understanding of site reliability terminology, operational metrics, and collaborative blameless cultures.
Who should take it
Junior cloud engineers, transitioning software developers, and systems administrators aiming to establish a standardized operational vocabulary.
Skills you’ll gain
- Defining accurate Service Level Indicators and Service Level Objectives.
- Implementing comprehensive basic monitoring and alert threshold structures.
- Conducting thorough, constructive blameless post-mortem investigations.
Real-world projects you should be able to do
- Construct an operational dashboard mapping application health to specific business metrics.
- Author an actionable, structured incident response runbook for an active application failure scenario.
Preparation plan
- 7–14 days: Review official core terminology documentation, complete practice quiz questions daily, and master basic error budget mathematics formulas.
- 30 days: Read foundational operations textbooks, configure basic telemetry collectors on local virtual environments, and study real-world incident post-mortems.
- 60 days: Dedicate time to running end-to-end simulated outages on personal servers, refining alert rules, and participating in peer study groups.
Common mistakes
Candidates often spend too much time memorizing cloud provider command-line flags while neglecting the mathematical concepts behind error budget consumption.
Best next certification after this
- Same-track option: Certified Site Reliability Engineer – Professional
- Cross-track option: Certified Automation Specialist
- Leadership option: SRE Team Lead Certification
Certified Site Reliability Engineer – Professional
What it is
This level validates an engineer’s capability to build automated pipelines, manage stateful cloud applications, and handle complex live incidents under pressure.
Who should take it
Mid-level DevOps specialists and systems engineers with multiple years of experience managing production infrastructure.
Skills you’ll gain
- Building self-healing infrastructure automation routines.
- Orchestrating containerized microservices deployments with advanced deployment patterns.
- Configuring deep tracing mechanisms across distributed microservices architectures.
Real-world projects you should be able to do
- Deploy a fully automated canary release pipeline that triggers automatic rollbacks based on live error rates.
- Configure a distributed tracing fabric across a multi-tier microservices application to isolate latency bottlenecks.
Preparation plan
- 7–14 days: Concentrate intensively on advanced scripting syntax, container configuration flags, and review complex network troubleshooting methods.
- 30 days: Build end-to-end continuous delivery infrastructure utilizing mock microservices, intentionally breaking configurations to practice rapid restoration.
- 60 days: Execute comprehensive simulated production runs, analyze architectural failures in mock systems, and study deep packet analysis tools.
Common mistakes
A frequent mistake is failing to write clean, modular automation scripts during the practical exam phases, resulting in unmaintainable configurations.
Best next certification after this
- Same-track option: Certified Site Reliability Engineer – Advanced
- Cross-track option: Certified Security Operations Professional
- Leadership option: Principal Infrastructure Architect Program
Certified Site Reliability Engineer – Advanced
What it is
This advanced credential certifies an architect’s capacity to design fault-tolerant global systems, lead chaos engineering experiments, and govern enterprise-wide reliability initiatives.
Who should take it
Principal engineers, enterprise infrastructure architects, and senior practitioners responsible for organizational uptime targets.
Skills you’ll gain
- Designing globally distributed, multi-region active-active cloud deployment architectures.
- Architecting safe, continuous chaos engineering experiments within active production environments.
- Establishing corporate-wide governance frameworks for systemic reliability and technical debt reduction.
Real-world projects you should be able to do
- Architect and execute an automated chaos engineering experiment that safely drops an entire cloud zone without customer impact.
- Redesign a monolithic legacy infrastructure pattern into a highly resilient, geographically isolated multi-region topology.
Preparation plan
- 7–14 days: Analyze advanced architectural whitepapers focusing exclusively on global consensus algorithms and distributed state management.
- 30 days: Build sandboxed multi-region test environments to evaluate complex failover automation scripts and data synchronization lag metrics.
- 60 days: Review historical enterprise infrastructure failure case studies, map failure modes, and run deep simulations of split-brain database scenarios.
Common mistakes
Candidates often focus too narrowly on specific cloud software tools instead of evaluating high-level architectural failure modes and systemic risks.
Best next certification after this
- Same-track option: Emeritus Systems Fellow Certification
- Cross-track option: Enterprise FinOps Director
- Leadership option: Director of Platform Engineering Program
Choose Your Learning Path
DevOps Path
This path focuses heavily on building continuous delivery pipelines that integrate reliability metrics right into the build cycle. Engineers will learn how to turn operational thresholds into automated gatekeepers for software deployments. This eliminates unstable code before it ever reaches production environments. Over time, practitioners become experts at infrastructure as code and deployment safety.
DevSecOps Path
This trajectory merges traditional reliability strategies with strict security governance frameworks throughout the software lifecycle. Candidates learn how to automate secret management, enforce access controls, and perform non-disruptive vulnerability scanning during active incidents. It ensures that system hardening does not compromise application performance or operational velocity. This path is ideal for professionals operating within heavily regulated enterprise environments.
SRE Path
The pure operational track centers on maintaining system availability, optimizing latency, and managing capacity efficiency. Practitioners master systemic incident response, advanced observability instrumentation, and systemic failure domain isolation. This learning path turns engineers into elite troubleshooters capable of navigating highly complex distributed environments. It emphasizes a strict engineering-centric approach to resolving infrastructure challenges.
AIOps Path
This path leverages machine learning frameworks to parse massive streams of telemetry logs, metrics, and trace histories. Engineers learn to train analytic models that detect operational anomalies before they manifest as critical consumer outages. It moves an organization away from reactive alerts toward true predictive remediation workflows. This track represents the cutting edge of intelligent enterprise system maintenance.
MLOps Path
Focused specifically on the lifecycle management of machine learning models, this track ensures production pipeline reliability. Engineers learn how to monitor model drift, automate training data pipelines, and maintain highly scalable inference endpoints. It bridges the gap between data science experimentation and hardened production delivery infrastructure. This path is essential for organizations embedding artificial intelligence into core product offerings.
DataOps Path
This track applies reliability engineering principles directly to complex data lakes, real-time analytics streaming pipelines, and enterprise databases. Professionals learn to monitor data quality, manage schema migrations without downtime, and orchestrate large-scale data transformation workflows reliably. It ensures that downstream analytical systems receive accurate information without processing delays. This path solves the unique operational challenges of large-scale data architectures.
FinOps Path
This specialized framework combines financial accountability with cloud infrastructure configuration choices to maximize efficiency. Engineers develop the technical skills required to track resource utilization, identify idle assets, and automate cost-optimization workflows across multiple cloud providers. This path teaches teams how to scale infrastructure responsibly without incurring unexpected budget overruns. It directly aligns technical architecture decisions with corporate financial realities.
Role → Recommended Certified Site Reliability Engineer Certifications
| Role | Recommended Certifications |
| DevOps Engineer | Foundation + Automation Professional Track |
| SRE | Full Core Tier (Foundation, Professional, Advanced) |
| Platform Engineer | Core Professional + Advanced Architecture |
| Cloud Engineer | Foundation + Automation Track |
| Security Engineer | Foundation + DevSecOps Specialist Track |
| Data Engineer | Foundation + DataOps Track |
| FinOps Practitioner | Foundation + FinOps Track |
| Engineering Manager | Foundation + Strategic Governance Frameworks |
Next Certifications to Take After Certified Site Reliability Engineer
Same Track Progression
Once you master a specific operational level, the logical progression is to advance deeper vertically into advanced architecture design. Moving from foundational tracking to professional execution, and finally arriving at advanced system engineering ensures complete mastery of operational domains. This path establishes you as the definitive technical authority on systemic infrastructure reliability inside your enterprise.
Cross-Track Expansion
To build a highly versatile skill set, engineers should branch out horizontally into adjacent operational disciplines. Combining core engineering knowledge with specialized training in financial optimization, security compliance, or intelligent data management creates a unique professional profile. This cross-functional visibility allows you to solve multifaceted organizational challenges that cross traditional team boundaries.
Leadership & Management Track
For senior professionals looking to move away from day-to-day command-line configuration, transitioning to strategic leadership paths is highly effective. Focus on certifications that teach team building, organizational design, financial budgeting, and high-level platform engineering governance. This shift positions you perfectly to command entire engineering organizations, run global platform teams, or step into enterprise director roles.
Training & Certification Support Providers for Certified Site Reliability Engineer
DevOpsSchool provides deep, instructor-led training programs focused on hands-on lab environments and comprehensive continuous delivery pipeline building.
Cotocus specializes in delivering tailored enterprise-grade training bootcamps designed to upskill entire engineering teams on modern cloud architectures.
Scmgalaxy offers an extensive repository of technical articles, community forums, and practical step-by-step guides covering diverse configuration management challenges.
BestDevOps focuses on delivering highly curated, job-ready certification preparation courses that simulate modern infrastructure engineering interview environments.
devsecopsschool concentrates on injecting comprehensive security protocols directly into standard operational workflows, providing deep cloud-hardening training programs.
sreschool stands as a premier platform offering structured learning paths designed specifically around system availability metrics and comprehensive incident mitigation practices.
aiopsschool teaches cutting-edge paradigms that leverage machine learning algorithms to automate complex corporate telemetry analysis and incident prediction matrices.
dataopsschool addresses the unique operational complexities of high-volume data streaming infrastructure, focusing heavily on analytics pipeline health.
finopsschool delivers highly specialized training aimed at cloud financial management, teaching engineers how to balance infrastructure performance against corporate budgets.
Frequently Asked Questions (General)
- What is the primary focus of this engineering program?The program focuses on applying rigorous software engineering principles directly to infrastructure design, incident mitigation, and operational scale challenges.
- How long does it typically take to prepare for the foundational exam?Most working professionals comfortably prepare for the foundational level exam within a structured timeline of thirty to sixty days of regular study.
- Are there practical coding exercises included during the evaluation process?Yes, the professional and advanced level evaluations feature rigorous performance-based tasks that require writing active configuration scripts and troubleshooting environments.
- Can software developers transition successfully into this operations ecosystem?Absolutely, software developers with a strong grasp of programming find this path highly rewarding as it teaches them how code behaves at scale.
- Is the foundational credential a strict prerequisite for the advanced tiers?Yes, the program enforces a sequential tier structure to ensure that candidates possess a solid understanding of core principles before attempting advanced architectures.
- How does this training differ from typical cloud provider certifications?Cloud provider certifications teach you how to use specific proprietary tools, while this curriculum focuses on universal architecture principles independent of vendors.
- What is the expiration timeline for these professional credentials?The certifications remain valid for a standard period of three years, after which professionals complete continuing education recertification paths.
- Are these certifications recognized by global enterprise employers?Yes, major enterprise organizations worldwide value these credentials because they demonstrate verifiable, practical engineering problem-solving abilities rather than simple theoretical knowledge.
- What industries find these operational skills most valuable?Any industry relying on high-availability digital infrastructure, such as finance, healthcare, e-commerce, and large-scale SaaS platforms, requires these skills.
- Does the curriculum cover modern container orchestration methodologies?Yes, container management systems and cloud-native architecture patterns form a substantial component of the professional and advanced learning tracks.
- Can technical managers benefit from completing the foundational level?Yes, engineering managers find the foundational tier highly valuable for learning how to design reliable metrics-driven team workflows.
- What kind of computer setup is required for the practical examinations?Candidates need a stable computer with reliable high-speed internet access capable of running modern browser-based terminal emulators smoothly.
FAQs on Certified Site Reliability Engineer
- How does the Certified Site Reliability Engineer program directly improve daily production uptime metrics?
The curriculum trains engineers to replace manual, error-prone operational interventions with automated, deterministic software systems. By mastering systematic incident response, error budget math, and self-healing infrastructure patterns, teams can dramatically lower their mean time to resolution and keep applications highly stable. - Does the Certified Site Reliability Engineer exam test specialized multi-cloud orchestration patterns?
Yes, the advanced levels focus extensively on building resilient configurations across multiple cloud environments. Candidates are tested on their ability to design vendor-agnostic systems that tolerate complete regional cloud data center outages without dropping customer traffic. - Can an engineer pass the Certified Site Reliability Engineer professional level using theoretical study alone?
No, the professional level contains interactive, live environment challenges where you must fix broken setups under time pressure. Candidates must demonstrate actual command-line troubleshooting skills and create functional automation routines to pass. - What mathematical formulas must a candidate master for the Certified Site Reliability Engineer credentials?
Candidates must thoroughly understand the mathematical frameworks used to calculate availability percentages, error budgets, and latency distributions. This includes translating business availability agreements into exact numbers of allowed downtime minutes per quarter. - How does the Certified Site Reliability Engineer framework address technical debt within enterprise software teams?
The training provides clear governance rules that help you manage technical debt objectively. It teaches teams how to use an error budget as a trigger: when a system becomes too unstable, feature development stops, and engineering effort redirects to reliability. - What is the value of the Certified Site Reliability Engineer credential within the Indian technology sector?
As enterprise teams across India shift from traditional IT support models to advanced platform engineering, demand for modern skills is skyrocketing. This certification provides Indian engineers with a globally recognized validation of their ability to manage complex cloud operations. - How regularly is the Certified Site Reliability Engineer curriculum updated to match industry changes?
The underlying structural principles remain consistent, but the practical testing environments are updated regularly by industry experts. This ensures that the simulation exams accurately reflect the latest stable cloud-native software toolsets and architectural patterns. - Are blameless post-mortem methodologies deeply evaluated in the Certified Site Reliability Engineer track?
Yes, cultural mastery is a core pillar of the foundational and professional tiers. The exam evaluates a candidate’s ability to analyze complex failures objectively, focusing on systemic software and process flaws rather than blaming human operators.
Final Thoughts: Is Certified Site Reliability Engineer Worth It?
Investing your time in the Certified Site Reliability Engineer ecosystem is a practical, calculated decision for anyone serious about managing production-grade systems. The industry has moved definitively away from manual operations toward automated, software-driven infrastructure. This program provides you with the mental frameworks, architectural principles, and automation strategies required to lead that transformation. Rather than chasing fleeting software trends, it builds a solid engineering foundation that remains highly valuable across any cloud provider platform. If your goal is to build resilient systems, reduce operational chaos, and advance into senior technical leadership roles, this certification path is an excellent choice.