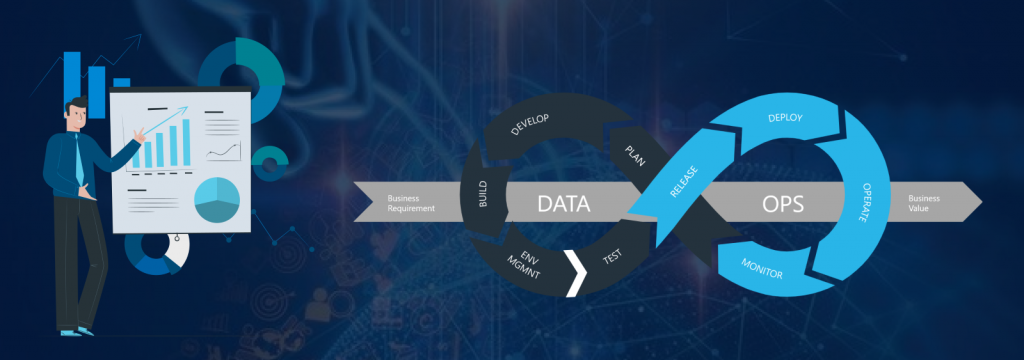
DataOps is an automated, process-oriented methodology that analytic and data teams use to improve data analytics quality and reduce cycle time. While DataOps began as a collection of best practices, it has evolved into a distinct and new approach to data analytics. DataOps refers to the entire data lifecycle, from data preparation to reporting, and recognizes the data analytics team’s and IT operations’ interconnected nature. DataOps uses the Agile methodology to reduce the time it takes to develop analytics that are aligned with business goals.
Origin & Evolution of DataOps
On June 19, 2014, Lenny Liebmann, Contributing Editor, InformationWeek, first mentioned DataOps in a blog post on the IBM Big Data & Analytics Hub titled “3 reasons why DataOps is essential for big data success.” Andy Palmer of Tamr and Steph Locke popularized the term DataOps later. “Data Operations” is referred to as “DataOps.” With significant ecosystem development, analyst coverage, increased keyword searches, surveys, publications, and open-source projects, 2017 was a significant year for DataOps. DataOps was named to Gartner’s Hype Cycle for Data Management in 2018.
What is DataOps?

DataOps is a set of technical practices, workflows, cultural norms, and architectural patterns that allow you to do the following: Rapid innovation and experimentation, with increasing velocity in delivering new insights to customers Exceptionally high quality and low error rates Collaboration among a diverse group of people, technologies, and settings Clear results measurement, monitoring, and transparency Reviewing DataOps’ intellectual history, exploring the problems it seeks to solve, and describing an example of a DataOps team or organization are the best ways to explain it. Our explanations begin at a conceptual level and quickly progress into pragmatic and practical terms. This, we believe, is the most effective way of assisting data professionals in comprehending the potential benefits of DataOps.
What Problem is solved by DataOps?
Limited collaboration- Implementing DataOps workflows increases collaboration between data-focused teams and Development-focused teams. At it’s best, in fact, DataOps aims to eliminate the distinction between these two business functions. Critical to realizing this, though, is an underlying process of goal-setting. Both development staff and the data team need to collaboratively develop an overview of the data acquisition journey through your organization, so that both can see where the work of the other can be used to improve their own work.
Bug fixing- While DataOps is most commonly associated with increasing the efficiency and agility of development processes, it also has a lot of applications in incident management. Fixing bugs and defects in your products is a time-sensitive business function that will likely require input from both data and development specialists. The time it takes to respond to bugs and defects can be drastically reduced with better communication and collaboration between these two staff groups. This is beneficial on a technical level, because data teams will be included in bug-fixing processes as soon as possible, but it is also beneficial in terms of reputation management, because data teams will be included in bug-fixing processes as soon as possible.
Slow responses- Responding to development requests – both from users and from higher management – is perhaps one of the most difficult challenges facing organisations today. Previously, requests for new features were sent back and forth between data scientists and the development team. Staff can collaborate on new requests because DataOps teams include both of these functions. This allows the development team to see how new features affect data flow throughout the organisation, and it can also assist data teams in focusing their processing on the enterprise’s actual goals.
Goal setting- When properly implemented, DataOps can provide real-time data on the performance of data systems to both development teams and management. These data aren’t just useful for tracking progress toward business objectives: if business processes are flexible enough, they can also be used to adjust and update performance goals in real time.
Efficiency- Organizational efficiency is harmed by all of the issues listed above. Each team would compile reports on their work in the old DevOps model, and these would be passed between multiple, hierarchical, vertically organised structures. DataOps allows data and development staff to collaborate horizontally, resulting in a horizontal information flow. Instead of comparing notes at monthly meetings, information is exchanged on a daily basis. This greatly improves an organization’s efficiency.
Why Do We Need DataOps?

The first reason we need DataOps – a streamlined, efficient process – is that in the business world, time is of the essence. There’s a reason why real-time data collection and analysis has received so much attention: things move quickly, and a new opportunity can appear and vanish in the blink of an eye.
We also have new standards for how quickly we should be able to access information. We live in an era where information is at our fingertips, and all it takes is a few swipes or taps to get what we want. If we can get answers online in seconds, we should be able to get our business intelligence data in the same amount of time.
Big data is also extremely varied and constantly changing, necessitating a reactive, adaptable system that can keep up. You could be working on machine learning and predictive analytics one day and processing transactions or analysing mobile data the next. You can stay on top of everything by connecting all of your teams with a unified DataOps system.
Finally, DataOps is all about getting the most out of your data. By forming collaborative groups, you’ll be able to create a future-proof system and a streamlined process that will help you get the most out of your data. As you discover new ways to use your data, your DataOps setup will put you ahead of the game and ensure you’re in the best position to capitalise.
How to implement DataOps?
In order to improve the use and value of data in a dynamic environment, DataOps automates the design, deployment, and management of data delivery with the appropriate levels of governance and metadata.
A data pipeline, which refers to the sequence of stages data goes through inside a project, starting with its extraction from various data sources and ending with its exposition or visualisation for business consumption, is at the heart of this process.
Using CI/CD practises, DataOps orchestrates and automates this pipeline to ensure it scales properly to production. As new data is added to the pipeline, the process is illustrated by a series of three loops in which data models are promoted between environments.
Loop #1 – Sandbox
Raw data is examined in order to generate a preliminary set of unrefined analyses. This allows data teams to be more inventive in probing the organization’s data for any potential value. Because the main focus is on fast experimentation rather than unquestionable validity, meticulous data cleaning, mapping, and modelling are not required at this time.
Loop #2 – Staging
Data is cleaned and documented appropriately, and initial models are refined through iterations to gradually improve their quality. Models are eventually validated when they are deemed reliable enough to go into production.
Loop #3 – Production
Finally, fully refined analytic models are advanced to the production stage, where data consumers can use them in their daily activities. They can use the knowledge they’ve gained to improve and speed up decision-making processes at the corporate level, resulting in long-term business value and ROI.
How DataOps Works and Architecture?
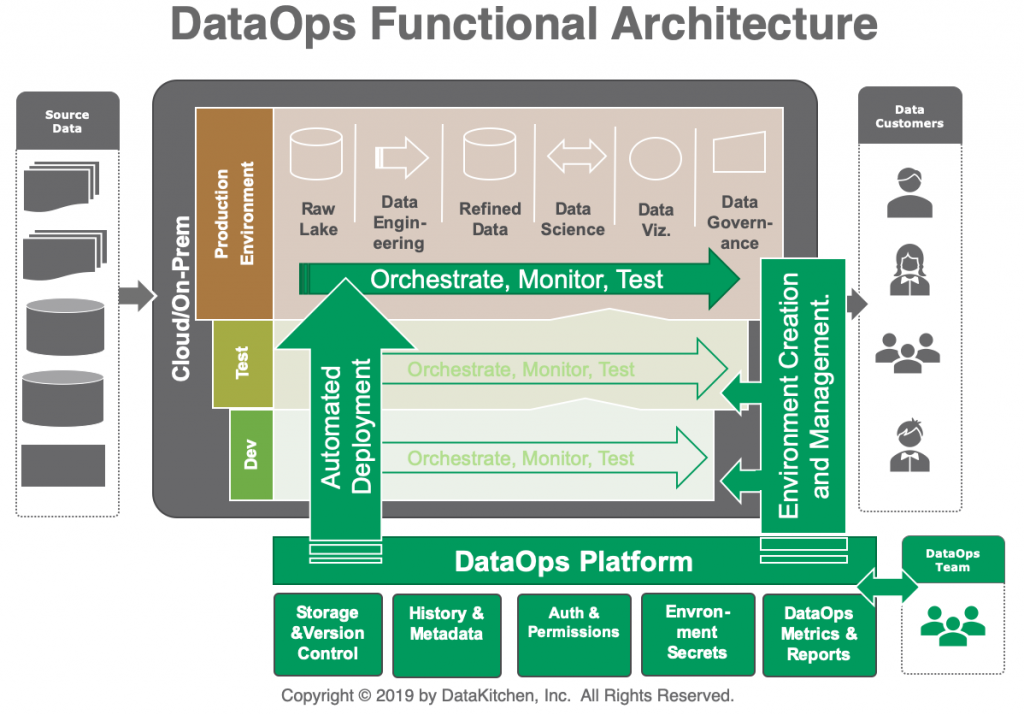
What are the top tools of Dataops?
Genie
The DataOps tool, created by Netflix, is an open-source engine that provides distributed job orchestration services. This tool provides RESTful APIs for developers who want to use Hive, Hadoop, Presto, and Spark to run a variety of Big Data jobs. In distributed processing clusters, Genie also provides APIs for metadata management.
Piper
Piper is a set of Machine Learning-based DataOps tools that help businesses read data more quickly and easily. This solution exposes data through a set of APIs that can easily be integrated with the organization’s digital assets. Furthermore, it combines batch and real-time processing to provide the most advanced data technologies as well as comprehensive support. Pipper, which focuses on AI, enables businesses to reduce data operations turnaround time and manage the entire software development lifecycle through its prepackaged data apps.
Airflow
Apache Airflow is an open-source DataOps platform that considers data processes as DAGs to manage complex workflows in any organisation (Directed Acyclic Graphs). Airbnb created this tool to help them schedule and monitor their workflows. On macOS, Linux, and Windows, organisations can now use this open-source tool to manage their data processes.
Naveego
Naveego is a cloud data integration platform that enables companies to make accurate business decisions by integrating all company data into a standard business-centric format. This tool cleans stored data and prepares it for data scientists to analyse. Naveego allows you to securely monitor and validate all of your company’s stored data.
FirstEigen
On the basis of self-learning, FirstEigen is a platform that includes Machine Learning tools for big data quality validation and data matching. This platform uses advanced machine learning techniques to learn about data quality behaviours and models, and then tests big data with just three clicks. Organizations can ensure the accuracy, completeness, and sanctity of their data as it moves across multiple IT platforms with FirstEigen.
RightData
RightData is a collection of self-service applications for data quality assurance, integrity auditing, and continuous control, as well as automated validation. This suite is best suited for companies looking for tools that can automate testing and reconciliation. Data migration, database upgrades, DAP, BI, reports, and much more can all be tested with RightData.
Badook
Badook is a popular tool among data scientists because it allows them to create automated tests for datasets used in data model training and testing. This tool not only allows them to automatically validate data, but it also reduces the time it takes to generate insights.
DataKitchen
DataKitchen is one of the most popular DataOps tools, and it’s ideal for automating and coordinating people, environments, and tools across the entire organization’s data analytics. From testing to orchestration, development, and deployment, DataKitchen has you covered. With this platform, your company can achieve near-zero errors and deploy new features faster than the competition. DataKitchen allows companies to create repetitive work environments in minutes, allowing teams to experiment without disrupting production. DataKitchen’s Quality pipeline is divided into three sections: data, production, and value.
Lentiq
This data model deployment tool is designed for smaller teams to use in a service environment. You can use Lentiq to run data science and data analysis in the cloud at any scale you want, allowing your team to ingest real-time data, process it, and share useful insights. Your team can train, build, and share models within the environment with Lentiq, and innovate without limits. For Lentiq model training, Jupyter Notebooks are recommended.
Advantages & Disadvantages of DataOps
Advantages
- Software delivery on a continuous basis
- There is less to manage.
- Problems are resolved more quickly.
- Teams that are happier and more productive
- Employee engagement is higher.
- Greater opportunities for professional development
- DataOps will help you understand your data and what it represents better.
- DataOps will increase the speed of IT projects by automating data.
- DataOps will decrease fragility by standardizing and repeating data tasks.
- DataOps will improve testing by using data and patterns that are similar to those used in production.
- DataOps will ensure that PII is protected in accordance with industry regulations, such as GDPR.
- DataOps will ensure the security of enterprise (and customer) data and risks.
- DataOps will ensure that “quality data” is available to aid AI and Machine Learning.
Disadvantage
Unrealistic Expectations: When it comes to pipelines, having unrealistic expectations can be difficult. To set up working and efficient pipelines, data scientists should have a strong operationalization understanding.
No visibility: More data often means more insights, which leads to more opportunities for growth. However, if the person dealing with this massive amount of data has no idea where it is, how it was used in the past, or how it is stored, a huge problem arises. It is necessary to understand all aspects of one’s data and to put in place the necessary systems for data governance.
Lack of Monitoring: DataOps is reliant on effective monitoring with attainable objectives. Addressing the source of a problem and standardizing success metrics can make or break a pipeline. The AI-powered data pipeline is assisting with the load, but DataOps implementation necessitates an integrated approach from business stakeholders.
Roles & Responsibilities in DataOps
As organisations attempt to operationalize more data, the DataOps engineer is a relatively new role that is growing in importance. While data scientists and analysts can assist the company in gaining more business value from data, they must first gather data sets from various sources and use them at scale in a controlled manner. In short, the DataOps engineer’s responsibilities tend to be outside the scope of other members of the data team. A DataOps engineer’s job is now slightly different from that of a data engineer. The DataOps engineer meticulously defines and manages the data development environment. In addition, the role entails providing data engineers with workflow guidance and design support. When it comes to advanced enterprise analytics, DataOps engineers are crucial to automating data development and integration. DataOps engineers contribute to enterprise analytics by tracking document sources through metadata cataloguing and building metric platforms to standardize calculations, thanks to their extensive knowledge of software development and agile methodologies. A DataOps engineer’s main responsibilities include:
- Automated testing
- The establishment of code repositories
- Orchestration of the framework
- Workflow management and collaboration
- Analysis of the lineage and the impact
- Preparation and integration of data
Future of DataOps in Software Engineering

The mindset of the people who make up the organization determines the future and adoption of DataOps in the tech industry. Spending less time thinking about technology and more time thinking about people and culture issues may help organizations deliver data that users will use, resulting in meaningful returns on their Big Data investments. “An organization’s ability to learn, and translate that learning into action quickly, is the ultimate competitive advantage,” said Jack Welch, former CEO of GE. People create value, not the other way around.
Career Scope in DataOps
Data engineers are crucial in ensuring that data is properly managed throughout the analytics process. They’re also in charge of making the best use of data and ensuring its security. DataOps aid data engineers in their key functional areas by providing end-to-end orchestration of tools, data, codes, and the organizational data environment. It can improve team collaboration and communication in order to respond to changing customer needs. Simply put, DataOps strengthens data engineers’ hands by facilitating greater collaboration among various data stakeholders and assisting them in achieving reliability, scalability, and agility.
Data Ops, also known as data operations, is a DevOps-based agile methodology for designing, implementing, and maintaining data in a distributed architecture. The main goal of this approach is to provide quick and accurate results on big data, which is received on a daily basis by businesses, and to extract useful analytics.
Overall, DataOps is a gateway to a world of smarter products. Organizations can now use fully managed platforms to build autonomous data pipelines that power both analytics and machine learning applications. Companies must use DataOps platforms so that their teams can easily adopt and collaborate while working with massive datasets on a regular basis.